Generatieve AI-modellen zoals ChatGPT en Bard kunnen verbluffend mensachtige teksten schrijven, code genereren en complexe vragen beantwoorden. Maar wie ze regelmatig gebruikt, heeft misschien gemerkt dat deze modellen soms ook “hallucineren”. Dat betekent dat ze zelfverzekerde antwoorden geven die feitelijk onjuist of volledig verzonnen zijn. In dit artikel leg ik op een toegankelijke manier uit wat zulke AI-hallucinaties zijn en waarom ze problematisch kunnen zijn. Daarna duik ik in Retrieval-Augmented Generation (RAG), een veelbelovende techniek die generatieve AI helpt om minder te hallucineren en betrouwbaardere, up-to-date antwoorden te geven. Ik houd het praktisch en begrijpelijk, met voorbeelden zoals een slimme chatbot die dankzij RAG altijd over actuele kennis beschikt.
Wat zijn AI-hallucinaties?
AI-hallucinaties treden op wanneer een generatief model een antwoord verzint dat niet gebaseerd is op feitelijke informatie. Het model presenteert dan iets dat geloofwaardig klinkt maar onjuist of niet bestaand is. Bijvoorbeeld: een AI kan een bron citeren die niet bestaat, een historisch “feit” verzinnen of met overtuiging een totaal fout antwoord geven. Dit gebeurt omdat zo’n AI geen echte kennis heeft, maar patronen herkent in tekst. Het weet niet wat waar of onwaar is. Als de juiste informatie ontbreekt, probeert het toch een logisch klinkend antwoord te geven. Het raadt dus eigenlijk wat waarschijnlijk zou kunnen kloppen.
Een bekend voorbeeld is een chatbot die een vraag krijgt waarvan het antwoord niet in zijn kennis zit. In plaats van te zeggen dat het iets niet weet, geeft de AI toch een antwoord. Dat antwoord klinkt vaak netjes en overtuigend, maar kan inhoudelijk helemaal niet kloppen.
Stel bijvoorbeeld dat je een chatbot vraagt naar een wet, product of gebeurtenis die nog niet bestaat of pas net is ingevoerd. De AI kan dan een uitleg geven die logisch klinkt, met verzonnen details of regels. Het lijkt alsof het antwoord klopt, maar in werkelijkheid is het gebaseerd op aannames.
De AI doet dit niet expres. Het systeem is zo gebouwd dat het altijd probeert te antwoorden, ook als het de juiste informatie mist. Zulke verzonnen antwoorden noemen we AI-hallucinaties.
Waarom zijn hallucinerende AI-antwoorden een probleem?
In een informele chat met een AI kunnen grappige of vreemde fictieve antwoorden onschuldig lijken. Maar hallucinerende AI vormt een serieus probleem zodra mensen op de output gaan vertrouwen. In professionele of gevoelige contexten, denk aan medisch advies, juridisch documenten of bedrijfsrapporten, kan een verzinsel grote gevolgen hebben. Foutieve informatie kan de gebruiker misleiden en daardoor zorgen voor verkeerde beslissingen.
Bovendien ondermijnen hallucinerende antwoorden het vertrouwen in AI-systemen. Als je AI-assistent soms dingen uit zijn duim zuigt, zul je elke output met argwaan bekijken. Onderzoekers die grote taalmodellen bestuderen, zoals teams van OpenAI en universiteiten die AI-systemen testen, laten zien dat deze modellen regelmatig overtuigend klinkende fouten maken.
Kortom, AI-hallucinaties zijn geen kleine foutjes, maar een echt probleem als je AI serieus wilt gebruiken. Daarom is de belangrijkste vraag: hoe zorgen we dat AI zo vaak mogelijk juiste antwoorden geeft? Daar komt Retrieval-Augmented Generation, kortweg RAG, om de hoek kijken.
RAG: AI die eerst opzoekt, dan antwoordt
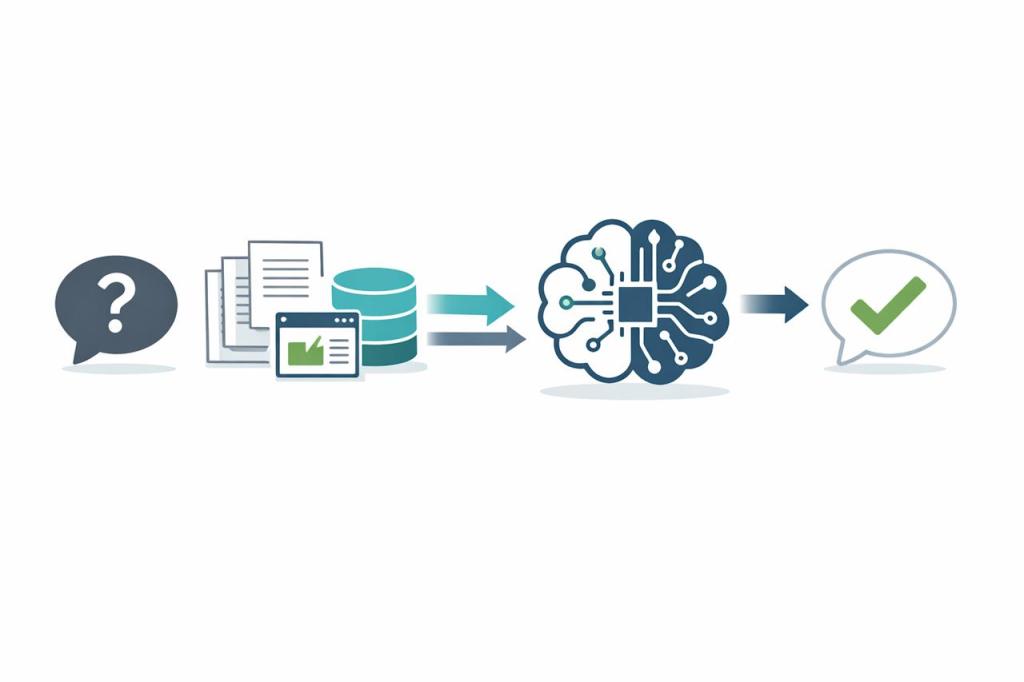
Retrieval-Augmented Generation, kortweg RAG, is een manier om AI betere antwoorden te laten geven. In plaats van alleen te vertrouwen op wat de AI ooit heeft geleerd, mag het systeem eerst informatie opzoeken voordat het antwoord geeft. Met andere woorden, RAG combineert de taalvaardigheid van een AI-model met de kracht van een zoekmachine of database. Het resultaat is een systeem dat nog steeds vloeiende tekst genereert, maar dan ondersteund door echte, relevante data in plaats van louter door wat het ooit heeft geleerd.
Hoe werkt RAG stap voor stap?
Een RAG-systeem doorloopt grofweg de volgende stappen wanneer het een vraag beantwoordt:
- Vraag van de gebruiker. Je stelt een vraag aan de AI, bijvoorbeeld: “Wie won de marathon van Rotterdam in 2025?”
- Zoekactie naar informatie. In plaats van direct een antwoord te genereren uit zijn trainingsgegevens, voert het systeem eerst een gerichte zoekactie uit. Het zoekt in een externe kennisbron, dat kan een interne database, verzameling documenten of het internet zijn, naar informatie die relevant is voor jouw vraag.
- Relevante data ophalen. Uit die zoekactie komen één of meerdere documenten, artikelen of tekstfragmenten naar voren met mogelijke antwoorden. Deze relevante content wordt verzameld: bijvoorbeeld een nieuwsbericht met de marathonuitslag, of een Wikipedia-pagina over de marathon.
- Antwoord genereren met bronnen. Nu treedt het taalmodel (LLM) weer op de voorgrond. Het krijgt zowel jouw oorspronkelijke vraag als de gevonden tekstfragmenten als input. Op basis daarvan formuleert het model het antwoord, waarbij het de opgehaalde feiten verwerkt in een samenhangend geheel. Het eindresultaat is een antwoord dat niet alleen taalkundig vloeiend is, maar ook onderbouwd met echte informatie.
Door deze aanpak kan het systeem antwoorden geven die veel beter onderbouwd zijn en gebaseerd op de meest recente beschikbare informatie. Eigenlijk is RAG dus een slimme combinatie van een zoekmachine en een geavanceerd taalmodel, waardoor het antwoord zowel natuurlijk geformuleerd is als feitelijk juist (of in elk geval controleerbaar aan de hand van bronnen). Cruciaal: de AI “weet” dankzij RAG wanneer het iets niet weet en kan dan actief op zoek gaan naar data, in plaats van maar wat te raden op basis van oude kennis. Daardoor worden de antwoorden flexibeler en betrouwbaarder.
Up-to-date en domeinspecifiek
Een groot voordeel van RAG is dat de AI niet langer vastzit aan verouderde kennis die tot een bepaalde datum is bijgewerkt. Heeft jouw model bijvoorbeeld trainingsdata tot 2021, dan zal het zonder RAG niets weten over gebeurtenissen in 2022 of 2023 en daarna. Met RAG kan het model actuele informatie opvragen. Stel dat je iets vraagt over het laatste wereldkampioenschap voetbal of de nieuwste smartphone-release, een traditioneel model zou mogelijk hallucineren of geen antwoord geven, maar een RAG-model kan de recente feiten opzoeken en je het juiste, up-to-date antwoord presenteren. Het resultaat: een AI die meekan met de actualiteit.
Daarnaast blinkt RAG uit in domeinspecifieke kennis. Je kunt een RAG-systeem laten zoeken in een specifieke collectie documenten. Denk aan medische artikelen voor een zorg-Chatbot, juridische dossiers voor een legal assistant, of interne bedrijfswikis voor een chatbot die medewerkers van dat bedrijf kunnen gebruiken voor hun dagelijkse werk. Zo’n AI haalt dan precies de vakinformatie of bedrijfsdata op die nodig is, en baseert daar zijn antwoord op. Zo blijven antwoorden correct binnen de context en zeer gericht. Een voorbeeld: een ziekenhuis gebruikt een RAG-chatbot die direct zoekt in de eigen medische databases en de nieuwste onderzoeken; een arts die via de chatbot een vraag stelt krijgt zo een antwoord dat gebaseerd is op de allerlaatste medische kennis in plaats van verouderde feiten. Dit principe geldt voor allerlei sectoren, van gezondheidszorg tot juridische advies, en maakt AI een stuk praktischer in professioneel gebruik.
Hoe voorkomt RAG hallucinerende antwoorden?
De reden dat RAG minder verzonnen antwoorden geeft, is grounding. Dat betekent dat de AI zijn antwoorden baseert op echte informatie. Omdat het generatieve model zijn antwoord baseert op daadwerkelijk opgehaalde inhoud, neemt het veel minder zijn toevlucht tot gokken of verzinnen. Met RAG is ieder antwoord in principe herleidbaar tot echte bronnen: het model heeft de relevante stukken tekst immers letterlijk opgehaald en gebruikt. Dit betekent dat het antwoord niet zomaar uit de lucht komt vallen, maar gebaseerd is op gegevens die jij (of de ontwikkelaars) hebt goedgekeurd.
Concreet vertaalt dit zich in een flinke afname van hallucinaties. Waar een standaard AI-model soms “geloofwaardige onzin” genereert, zal een RAG-model dat veel minder doen omdat het de neiging onderdrukt om gaten zelf in te vullen. Het vult de gaten liever op met echte info uit de kennisbank. RAG verkleint de kans op hallucinaties aanzienlijk door de output van het model te baseren op feitelijke, relevante inhoud. Het giswerk dat tot verzinsels leidt, wordt vervangen door gericht zoekwerk.
Bijkomend voordeel: omdat RAG de AI toestaat externe bronnen te raadplegen, hoeft men het model niet voortdurend volledig opnieuw te trainen om het up-to-date te houden. Nieuwe kennis kan gewoon aan de externe database toegevoegd worden, en de AI heeft er meteen toegang toe bij het beantwoorden. Dit maakt RAG niet alleen effectief tegen hallucinaties, maar ook efficiënt en schaalbaar in het onderhoud van AI-systemen. In plaats van na elke belangrijke ontwikkeling een modelupdate te doen, zorg je er simpelweg voor dat je kennisbank actueel is, de AI haalt de rest zelf wel op. Zo blijven de antwoorden kloppend en up-to-date, zonder dat de AI zelf alles “van binnenuit” hoeft te weten.
Praktisch voorbeeld: een chatbot met actuele kennis dankzij RAG
Stel je een eenvoudig scenario voor om het verschil te zien. Je vraagt aan twee AI-chatbots, eentje zonder RAG en eentje met RAG, de volgende vraag:
“Wie won de finale van de Champions League dit jaar?”
Zonder RAG: De eerste chatbot heeft een vaste kennisstand tot bijvoorbeeld 2021. Jouw vraag gaat over een recent evenement (stel, de Champions League van 2024). Het model weet het niet vanuit zijn training, die informatie zit er niet in. Toch probeert het misschien een antwoord te geven. Het zou kunnen gokken op basis van historische patronen (“Real Madrid wint vaak, dus misschien waren zij het”) en komt zo met een mogelijk onjuist antwoord. Of het model verzint een zeer overtuigend klinkend maar compleet verkeerd detail (“De finale van 2025 werd gewonnen door FC Imaginary met 3-2”). Dit antwoord ziet er qua zinsbouw prima uit, maar is hallucinatie en totaal onbetrouwbaar.
Met RAG: De tweede chatbot werkt met Retrieval-Augmented Generation. Die zal jouw vraag analyseren en beseffen dat het om een feitelijke, actuele kennisvraag gaat. Vervolgens voert het automatisch een zoekopdracht uit in een relevante bron, bijvoorbeeld in online nieuwsartikelen of een sportuitslagen-database. Het systeem vindt het verslag van de Champions League-finale van 2024, haalt de benodigde details op (welke clubs speelden, wat was de score, wie won). Daarna genereert de AI een keurig antwoord, zoals: “De Champions League finale van 2024 werd gewonnen door Real Madrid met 2-0.” Dit antwoord is onderbouwd met een echte bron (het nieuwsartikel) en is daardoor accuraat. De chatbot kan zelfs een referentie of bronlink erbij geven voor transparantie, zodat je desgewenst kunt controleren of het klopt.
In dit voorbeeld zie je dat de RAG-chatbot een up-to-date en betrouwbaar antwoord geeft, terwijl de traditionele AI mogelijk een foutief antwoord hallucineert of helemaal niet weet wat te zeggen. Dit principe geldt niet alleen voor sportuitslagen. Of je nu vraagt naar “het laatst uitgekomen model smartphone”, “nieuwe wijzigingen in de belastingwetgeving” of “de huidige status van een vlucht”, een RAG-systeem zal steeds de recentste informatie kunnen raadplegen en een feitelijk juist antwoord formuleren. Zonder RAG zou de AI bij dergelijke vragen vast kunnen lopen of iets verzinnen, zeker als de informatie na de trainingsperiode ligt.
Een ander praktisch voorbeeld binnen bedrijven. Stel dat een medewerker via een interne chatbot vraagt: “Wat is het actuele reisdeclaratiebeleid van ons bedrijf?” Een gewone AI-assistent kent misschien alleen algemene kennis en gaat een algemeen antwoord over onkostenvergoedingen geven, mogelijk fout voor dat specifieke bedrijf. Een RAG-aangedreven bedrijfsassistent daarentegen zal zoeken in de interne documentatie (beleidshandboeken, HR-portaal) en vervolgens antwoord geven met de precieze regels van het bedrijf, eventueel met een citaat uit het beleid. De medewerker krijgt direct het juiste antwoord, onderbouwd met het eigen bedrijfsdocument. Zo’n aanpak voorkomt dat de AI iets uit zijn duim zuigt over het beleid, het antwoord is immers direct gebaseerd op de echte documenten van de organisatie.
Slotopmerkingen: RAG als stap naar betrouwbare AI
Retrieval-Augmented Generation is een veelbelovende en enthousiasmerende ontwikkeling in de AI-wereld. Voor iedereen die net met AI begint, is het concept eigenlijk best gevoelsmatig: laat de AI eerst het goede antwoord opzoeken voordat hij iets zegt. Door deze koppeling van generatieve AI aan real-time informatiebronnen slaan we een brug tussen de taalkunsten van AI en de feitenkennis van de mensheid (zoals vastgelegd in databases en het web). Dit zorgt ervoor dat AI-antwoorden nuttiger én veiliger worden. Geen wonder dat RAG snel aan populariteit wint als dé manier om AI in te zetten in omgevingen waar nauwkeurigheid telt.
Moeten we dan voortaan blind vertrouwen op RAG-gevoede AI? Nee, dat ook weer niet. Hoewel RAG de kans op hallucinerende antwoorden sterk vermindert, is het geen magische “uit-knop” voor alle fouten. Als de externe bron foutieve informatie bevat, kan de AI die natuurlijk nog steeds overnemen. Daarom blijft goed databeheer, zoals uitgelegd in mijn artikel over het belang van Data Governance in AI, heel belangrijk. En als er niets relevants gevonden wordt, zou zelfs een RAG-systeem in theorie nog iets kunnen gaan verzinnen. Hoewel een goed ingestelde RAG-oplossing in zo’n geval gewoon zal aangeven dat het antwoord niet bekend is. Met andere woorden: hallucinaties zullen er altijd in enige mate zijn en menselijk oordeel blijft belangrijk.
Toch is RAG een grote stap vooruit. Het helpt AI om antwoorden te baseren op echte informatie, waardoor je de AI beter kunt vertrouwen. Als beginnende AI-enthousiasteling kun je RAG zien als een extra hulpmiddel dat AI “eerlijker” maakt: de AI kan nu zeggen “Laat mij even kijken…” in plaats van maar wat te verzinnen. Dit leidt tot nuttigere interacties en AI-antwoorden waar je met meer gerust hart op kunt bouwen. Met RAG wordt de samenwerking tussen mens en machine een stuk effectiever, de AI brengt taalvaardigheid en creativiteit, en via RAG brengen we de feiten in. Dat is een win-win voor iedereen die AI wil gebruiken als betrouwbare assistent. En dat is toch precies waar we naartoe willen met deze geweldige technologie!
Gerelateerde content
- De playlist ‘AI voor Beginners’ op mijn YouTube kanaal ‘De Wereld Van AI’
- Blog: Wat is Kunstmatige Intelligentie? Een Eenvoudige Introductie
- YouTube Video: Wat is Kunstmatige Intelligentie? (Eenvoudig uitgelegd)
- Blog: Wat is Retrieval-Augmented Generation (RAG)?
- Blog: Hoe Vectordatabases AI Verbeteren






Heb je een vraag of toevoeging? Reageer hieronder.